第一章
序言:新西兰奥克兰大学的两名教授开发了R语言,其中它可以用来进行数据处理、计算以及制图的免费软件。Meta分析的软件主要是Review Manager(简称 Rev Man )与STATA 。由数据操作、图形和计算等功能可以合在一起整合而成的常用的R软件。其中比较重要的有数据存储和处理功能等一些功能,在数据结构中(特别是矩阵)具有比较有用的地位,R中的分析工具都比较完善,所以R的功能比较强大是在分析数据和显示提供中,这一编程语言从语句和一些功能都比较完整、简容易、有效。
R语言的元包中的meta分析和剂量反应meta分析。 R语言使用的增加,meta分析的类型不断扩展,软件也逐渐发展起来。R语言具备运算、数据处理和作图的功能,可通过Linux、Machintosh、Windows系统等。目前,Windows系统等。 目前,R语言有Meta,Metafor,Rmeta等元数据分析软件包,但Meta软件包的功能,灵活性和适用范围非常广泛。
第二章
1.R软件及meta程序包的安装
首先到官网下载R软件,在你下载完后,选择安装按钮并双击打开安装文件,然后选择适合你的语言,通常我们选择简体中文,在了解自己的电脑打的性能后,选择适合你电脑的类型进行安装的组件,以防万一通常我建议四个都安装最好,以后不会因为少装了而去重新安装。对于大多的用户可以选择安装64位的,最重要的是要符合自己电脑的配置,你随便装哪个,我装了两个,都会用到。
在R软件中安装meta包:
Install.package(“meta”)
2.数据的输入
R中数据源的输入有:1.有键盘输入 2.从文本导入 3.导入Excel数据。
2.1键盘输入:
mydata <- data.frame(age=numeric(0)
+gender=character(0)
+weight=numeric(0))
>mydata <- edit(mydata)
Warning message:
In edit.data.frame(mydata) : added factor levels in 'gender'
> mydata
age gender weight
1 25 m 123
2 20 f 125
3 18 f 110
2.2从文本输入:
Data <- read.table(“f:/data/people.tex”,header=TRUE,sep=”,”)
2.3导入Excel数据:
Datal <- read.table(“f:/data/bus_sample.xlsx”,header=TRUE,sep=”,”)
读取Excel数据文件。第一将要用到的资料的基本数据录入 Excel 表格中,需先用RODBC 包进行分辨,再从Excel中输入数据,其中最常用的方法是将 Excel 文件另存为“TXT(制表符分隔)”或者“CSV(逗号分隔)”文件。
Data <- read.csv(“f:/data/bus_sample.csv”,header=TRUE,sep=”,”)
从Excel导入数据有两种常用方法,首先介绍剪贴板的方法。在电脑中打开Excel中电子表格通过剪贴板来选中需要的数据区域,再复制到剪贴板中导入数据。最后在软件R中键入命令:mydata <- read.delim (“ clipboard ”)其实通过这种方法导入的数据的步骤还是挺简单的。
第二种方法是使用R软件中RODBC的程序包,从E盘R文件夹中找到需要的文件导入,如名为Fleiss93的xls文件sheet1表。在载入RODBC包是,需先在R中键入命令:z<-odbcConnectExcel("E :/R/Fleiss93.xls")mydata<-sqlFetch(z,"Sheet1")
3.Meta分析方法介绍
R 的基础包中只包含了一些很基本的功能,Meta分析的合并效应量可以汇总好几个研究结果,其中要对研究问题的明确、了解相关的信息并验证关联的研究和标准,从而得出想要结果再汇总基本信息、分析结果得出结论。Meta分析最先在教育领域中使用。人们在临床试验实在二十世纪八十年代中期开始使用。其中在近些年,在医学领域大约有好几百论文涉及meta分析发表。Meta分析在经过几十年的发展在公共健康和个人相关的方面具有不错的成就,meta分析的科学化对临床实践和卫生决策中具有不可代替的作用。
Meta分析的统计学目的
meta分析可以进行汇总和合并分析,并同时可以对多个同类进行独立研究,样本含量自然就得到了提升,目的就是为了增加检验效能,当研究结果没有统计学意义时或研究结果多样化时,就需要采用meta分析就可得到统计分析结果更加接近真实情况的。
通常将meta分析的统计学异质性简称为“异质性”,它是以各研究之间可信区间(CI)的重合程度来度量异质性的大小。多个研究间的CI重合程度越大,存在统计异质性的可能性就越小,反之,各研究间就存在统计学异质性的可能性就越大。
R语言中现在可进行 Meta 分析的包有 meta 、 rmeta 、 metafor 、metacor 等。 本文主要介绍 meta 包。
以下是 meta 包中常用的命令
metabin :两分类资料的 Meta 分析
metacont :连续资料的 Meta 分析
forest :森林图绘制命令
metabias :分析中检验发表偏倚
funnel :漏斗图绘制命令
3.1.meta分析原理、方法和目的
Meta分析是指通过统计方法对收集的数据进行分析和推广,以提供回答研究问题的定量平均效应。 优点是通过增加样本内容以增加结论的置信度,结果的不一致性
Meta分析是对同一主题的几项独立研究的结果的系统,定量和综合分析。 它是一个定量的文献综述,基于对同一主题的一些独立研究的结果,并在严格的设计的基础上,我们使用适当的统计方法系统地,客观地和定量地分析多个研究的结果 。
方法:
(1)清楚和简洁要求解决该问题。
(2)一项随机对照试验,并广泛收集试验
(3)确定包含和排除标准,并排除不符合要求的文献。要明确包含和删除标准,并去掉不合规文件。
(4)数据选择和提取,包括数据的原始结果,图表等
(5)每次试验的质量评估和表征。
(6)统计学处理。
a.异质性检验(齐性检验)。
b.显示单次试验的结果和组合结论。
c.统计合并影响(加权合并,计算规模效应和95%置信区间)和统计推理。
d.敏感性分析。
e.通过计算“安全损失”或使用“反向漏斗”计算潜在出版物偏差。
(7)对结果和一些结论进行分析和总结。
(8)维护和更新资料。
目的:
增加的统计效力,因为个体临床试验趋向于在尺寸上更小,使得难以识别某些效果,并且这些效应对于临床医生可能是重要的。 解决研究结果的不一致。 寻找新的假设。
4.用法介绍
4.1 metabin(两分类资料的 Meta 分析)的命令
metabin ( event.e , n.e , event.c , n.c , studlab ,data=NULL , subset=NULL , method="MH" , sm=“ RR ”, incr=0.5 , allincr=FALSE , addincr=FALSE allstudies=FALSE , MH.exact=FALSE , RR.cochrane=FALSE , level = 0.95 , level.comb = level , comb.fixed=TRUE , comb.random =TRUE )
其中Meta包邮它本身的数据集,而溶解血栓剂的心肌梗塞一个数据集data(Olkin95),共有author,year, event.e, n.e, event.c, n.c等,分别代表作者,年份,实验组的有效数,实验组的总人数,对照组的有效数和对照组的总人数。
两分类资料的RR、OR、RD和AS差异值需要两分类资料的metabin命令metabin命令等语句才能够计算,同时MH、方差倒数和Peto方法为联合估计效应值。
4.2 metacont :连续资料的Meta分析
metacont ( n.e , mean.e , sd.e , n.c , mean.c , sd.c ,studlab ,data=NULL , subset=NULL , sm="MD" ,level = 0.95 , level.comb = level ,
comb.fixed=TRUE , comb.random=TRUE )
4.3常用的meta分析命令
R软件中的三大meta分析程序包中,metafor包的是最复杂,也是最多的,能完成很多高级meta分析功能,而meta包的命令和Stata中的metan命令类似,都容易使用,并且也能简单地对二分类资料进行meta分析的过程,并绘制森林图和漏斗图的同时,相反,在rmeta包中的命令程序则很少,它主要能对二分类资料进行meta分析。命令格式如下:
Meta分析命令数据,效应量、模型、研究名称
常用的效应量
OR:比值比(odds ratio)
RR:风险比或相对危险度(risk ratio或relative risk)
RD:风险差或率差(risk difference或ratio difference)
meafor包
(1)二分类资料的meta分析命令
固定效应模型:
Rma.mh(a,b,c,d,data=dataname,measure=“OR”,slab=studyname)
Rma.mh(a,b,c,d,data=dataname,measure=“RR”,slab=studyname)
Rma.mh(a,b,c,d,data=dataname,measure=“RD”,slab=studyname)
rma.mh表示使用Mantelope-Haenszel法进行固定效应模型分析。其中,a表示实验组发生事件数,b表示试验未发生事件数,c表示对照组发生事件数,d表示试验组未发生事件数:data=dataname表示使用的表格数据:measure=“OR”、measure=“RR”和measure=“RD”表示合并效应量为OR、RR、RD:slab=studyname标记每个研究。
随机效应模型:
Rma.umi(ai=a,bi=b,ci=c,di=d,data=dataname,measure=”OR”,method=”DL”,slab=studyname)
Rma.umi(ai=a,bi=b,ci=c,di=d,data=dataname,measure=”RR”,method=”DL”,slab=studyname)
Rma.umi(ai=a,bi=b,ci=c,di=d,data=dataname,measure=”RD”,method=”DL”,slab=studyname)
rmi.umi命令的参数method=“DL”表示使用Dersimonnian-Laird法进行随机效应模型分析。其中,ai=a表示实验组发生事件数,bi=b表示实验组未发生事件数,ci=c表示对照组发生事件数,di=d表示实验组未发生事件数;data=dataname表示使用的表格数据:measure=“OR”、measure=“RR”和measure=“RD”表示合并效应量为OR、RR或RD:slab=studyname标记每个研究。
连续性资料的meta分析命令
加权均数差(weighted mean difference,WMD)
标准化均数差(standardized mean difference,SMD)
WMD或SMD值的固定效应模型:
Rma.uni(n1i=n1,n2,m1i=mean1,m2i=mean2,sd1i=sd1,sd2i=sd2,data=dataname,measure=”MD”,method=”FE”,slab=studyname)
Rma.uni(nli=n1,n2,m1i=mean1,m2i=mean2,sd1i=sd1,sd2i=sd2,data=dataname,measure=”SMD”,method=”FE”,slab=studyname)
WND或SMD值的随机效应模型:
Rma.uni(nli=n1,n2,m1i=mean1,m2i=mean2,sd1i=sd1,sd2i=sd2,data=dataname,measure=”MD”,method=”DL”,slab=studyname)
Rma.uni(nli=n1,n2,m1i=mean1,m2i=mean2,sd1i=sd1,sd2i=sd2,data=dataname,measure=”SMD”,method=”DL”,slab=studyname)
rmi.umi命令的参数method=“DL”表示使用Dersimonnian-Laird法进行随机效应模型分析。其中,n1i=n1表示实验组样本含量,n2i=n2年表示实验组样本含量,吗m1i=mean1表示试验组均数,没m2i=mean2表示对照组均数;sdli=sd1表示试验组的标准差data=dataname表示使用的表格数据::measure=“MD”和measure=“SMD”表示合并效应量为MD或SMD:slab=studyname标记每个研究。
meta包
二分类资料的metabin命令
固定效应模型:
Metabin(a,n1,c,n2,data=dataname,sm=”OR”,comb.fixed=TURE,comb.random=FALSE,studlab=studyname)
Metabin(a,n1,c,n2,data=dataname,sm=”RR”,comb.fixed=TURE,comb.random=FALSE,studlab=studyname)
Metabin(a,n1,c,n2,data=dataname,sm=”RD”,comb.fixed=TURE,comb.random=FALSE,studlab=studyname)
OR、RR或RD值的随机效应模型:
Metabin(a,n1,c,n2,data=dataname,sm=”OR”,comb.fixed=FALSE,comb.random=TURE,studlab=studyname)
Metabin(a,n1,c,n2,data=dataname,sm=”RR”,comb.fixed=FALSE,comb.random=TURE,studlab=studyname)
Metabin(a,n1,c,n2,data=dataname,sm=”RD”,comb.fixed=FALSE,comb.random=TURE,studlab=studyname)
其中,a表示试验组发生事件数,n1表示试验组总样本量,c表示对照组发生事件数,n2表示对照组总样本量:data=dataname表示使用的表格数据:sm=“OR”、sm=“RR”和sm=”RD”分别表示合并效应量为OR、RR或RD:comb.fixed=TURE,comb.random=FALSE表示使用固定效应模型,comb.fixed=FALSE,comb.random=TURE表示使用随机效应模型:studlab=studyname标记每个研究。
连续性资料的metacont命令
WMD或SMD值的固定效应模型:
Metacont(n1,mean1,sd1,n2,mean2,sd2,data=dataname,sm=”MD”,comb.fixd=TURE,comb.random=FALSE,studlab=studyname)
Metacont(n1,mean1,sd1,n2,mean2,sd2,data=dataname,sm=”SMD”,comb.fixd=TURE,comb.random=FALSE,studlab=studyname)
WMD或SMD值的随机效应模型:
Metacont(n1,mean1,sd1,n2,mean2,sd2,data=dataname,sm=”MD”,comb.fixd=FALSE,comb.random=TURE,studlab=studyname)
Metacont(n1,mean1,sd1,n2,mean2,sd2,data=dataname,sm=”SMD”,comb.fixd=FALSE,comb.random=TURE,studlab=studyname)
其中,样本含量n1为试验组,试验组均值用mean1表示,标准差sd1表示试验组,样本含量n2为对照组,对照组均值用mean2表示,而sd2表示对照组的标准差:data=dataname表示使用的表格数据:sm=“MD”和sm=”SMD”分别表示合并效应量为MWD或SMD:comb.fixed=TURE,comb.random=FALSE表示使用固定效应模型,comb.fixed=FALSE,comb.random=TURE表示使用随机效应模型:studlab=studyname标记每个研究。
rmeta包
二分类资料的meta分析命令
固定效应模型meta。MH命令:
Meta.MH(n1,n2,a,c,data=dataname,names=studyname,statistic=”OR”)
Meta.MH(n1,n2,a,c,data=dataname,names=studyname,statistic=”RR”)
Meta.MH表示使用mantel-haenszel法进行固定效应模型分析。其中,n1表示试验组总样本量,n2表示对照组总样本量,a表示试验组发生事件数,c表示对照组发生事件数:data=dataname表示使用的表格数据:static=“OR”和static“RR”表示合并效应量为OR或RR:names=studyname标记每个研究。
OR或RR的随机效应模型meta.DSL命令:
Meta.DSL(n1,n2,a,c,data=dataname,names=studyname,static=”OR”)
Meta.DSL(n1,n2,a,c,data=dataname,names=studyname,static=”RR”)
Meta.dsl表示使用dersimonian-Laird法进行随机效应模型分析。其中,n1表示试验组总样本量,n2表示对照组总样本量,a表示试验组发生事件数,c表示对照组发生事件数:data=dataname表示使用的表格数据:static=“OR”和static“RR”表示合并效应量为OR或RR:names=studyname标记每个研究。
(2)连续性资料的meta分析命令:无
4.4.实例分析
例子1
进入R软件的数据编辑器,按列输入数据。其中,study表示研究名称,a表示试验组发生的事件数,b表示试验组未发生事件数,n1表示试验组总样本量,c表示对照组发生事件数,d表示试验组未发生事件数,n2表示对照组总样本量。
在R软件中创建一个名为“ror”的表格并输入数据,在R Console输入命令:
ror=data.frame(study=c("Lu2003","Wang2001","Shen2003","Gu2004","Ma1999"),a=c(11,2,13,26,20),b=c(41,28,29,34,30),n1=c(52,30,42,60,50),c=c(26,8,21,39,33),d=c(30,22,19,21,17),n2=c(56,30,40,60,50))
Ror回车得到如下:
ror
study a b n1 c d n2
1 Lu2003 11 41 52 26 30 56
2 Wang2001 2 28 30 8 22 30
3 Shen2003 13 29 42 21 19 40
4 Gu2004 26 34 60 39 21 60
5 Ma1999 20 30 50 33 17 50
metafor包:
Permutation 检验在R软件只有Metafor包可以执行。Permuta-tion 检验又称为置换检验,原假设H 0 需要从Permutation 检验的原理着手,检验统计量也必须从研究的问题中得出,近似分布可以通过模拟抽样和抽样分布中检验统计量其样本一般可以用排列组合的方法得到样本数据的概率,对此概率做出统计推断。Permutation 检验对原始数据的分布无要求,鉴于此优点,Follmann等,提出采用 Permutation 检验替代 Wald 及似然比检验(二者要求参数符合正态性),对 Meta 分析的模型参数进行检验。
install.packages("metafor")
library("metafor")
metaror=rma.mh(a,b,c,d,data=ror,measure="OR",slab=study)
metaror
Fixed-Effects Model (k = 5)
Test for Heterogeneity:
Q(df = 4) = 0.8432, p-val = 0.9326
Model Results (log scale):
estimate se zval pval ci.lb ci.ub
-1.0459 0.2018 -5.1832 <.0001 -1.4414 -0.6504
Model Results (OR scale):
estimate ci.lb ci.ub
0.3514 0.2366 0.5218
Cochran-Mantel-Haenszel Test: CMH = 26.3805, df = 1, p-val < 0.0001
Tarone's Test for Heterogeneity: X^2 = 0.8532, df = 4, p-val = 0.9312
R软件中metafor包OR的合并效应量
forest(metaror,transf=exp)
R软件中metafor包OR的森林图
funnel(metaror)

R软件中metafor包OR的漏斗图
meta包:
为了更好地理解 R 语言中 meta 包的功能,将R、STATA与RevMan三种软件Meta 分析功能进行比较。可使用Mantel-Haenszel 、 Peto 两种方法。对于连续型变量,三种软件均可使用WMD与SMD方法。对于数据录入格式,三个软件可使用频数(a、b、c、d)、估计值与标准差、估计值与可信区间。三个软件还可同时执行的有森林图、分层的森林图、方差齐性检验、I2统计量及分层Meta分析。另外,Meta回归、L’Abbe图、Galbraith图可以在R与STATA中实现,但不能在RevMan中实现。
library("meta")
metaror=metabin(a,n1,c,n2,data=ror,sm="OR",comb.fixed=TRUE,comb.random=FALSE,studlab=study)
> metaror
OR 95%-CI %W(fixed)
Lu2003 0.3096 [0.1326; 0.7227] 23.5
Wang2001 0.1964 [0.0378; 1.0198] 8.9
Shen2003 0.4056 [0.1646; 0.9993] 17.7
Gu2004 0.4118 [0.1972; 0.8599] 26.3
Ma1999 0.3434 [0.1522; 0.7751] 23.6
Number of studies combined: k = 5
OR 95%-CI z p-value
Fixed effect model 0.3514 [0.2366; 0.5218] -5.18 < 0.0001
Quantifying heterogeneity:
tau^2 = 0; H = 1.00 [1.00; 1.01]; I^2 = 0.0% [0.0%; 1.3%]
Test of heterogeneity:
Q d.f. p-value
0.84 4 0.9326
Details on meta-analytical method:
- Mantel-Haenszel method
R软件中meta包OR的合并效应量
forest(metaror)
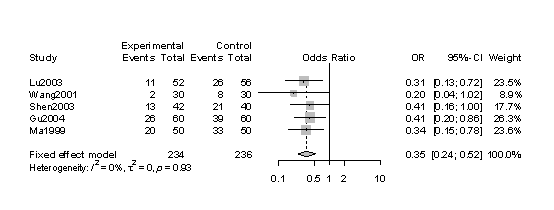
图中从左到右依次为单个试验(Study)、试验组(Exptexperiment)events表示发生事件数total表示总数;同样对照组(Ctrlcontrol)也是一样、比值比(OR)、权重(Weight)等。
试验结果的可信区间可以通过中间的短横线来表示,比值比(OR)用中部横线的小方块来表示。比值比(OR)的区间范围就是俗称的可信区间其代表比值比的真值,范围越宽,横线越长等指标来反应结果的精确性,如果结果欠精确可靠就表明样本的量较小。也就是说样本越大,范围越窄,横线越短,所得到的结果精确性就越可靠。Cochrane系统评价中使用的可信区间是95%或99%。
R软件中meta包OR的森林图
funnel(metaror)

R软件中meta包OR的漏斗图
从这个结果可以看出:在R软件中metafor和meta包中合并效应量OR值均为0.35,OR值95%可信区间是0.25~0.52。这个区间不包括1,可以认为合并的效应量OR值不等于1,从图中可以看出菱形和短横线位于OR中线的左边可以得出对不利结局是有效,对有利结局是无效。
rmeta 包:
rmeta 程序包中关于适用于固定效应模型计算的 Mantel-Haensel 法和 Peto 法两种计算方法的表述如下:对于二分类资料,至少有两种方法适用于固定效应模型。rmeta 程序包通过“forestplot() 函数”和“funnel-plot() 函数”绘制森林图和漏斗图
library("rmeta")
Loading required package: grid
> metaror=meta.MH(n1,n2,a,c,data=ror,names=study,statistic="OR")
> summary(metaror)
Fixed effects ( Mantel-Haenszel ) meta-analysis
Call: meta.MH(ntrt = n1, nctrl = n2, ptrt = a, pctrl = c, names = study,
data = ror, statistic = "OR")
------------------------------------
OR (lower 95% upper)
Lu2003 0.31 0.13 0.72
Wang2001 0.20 0.04 1.02
Shen2003 0.41 0.16 1.00
Gu2004 0.41 0.20 0.86
Ma1999 0.34 0.15 0.78
------------------------------------
Mantel-Haenszel OR =0.35 95% CI ( 0.24,0.52 )
Test for heterogeneity: X^2( 4 ) = 0.84 ( p-value 0.9326 )
R软件中rmeta包OR的合并效应量
plot(metaror)

R软件中rmeta包OR的森林图
funnelplot(metaror)

R软件中rmeta包OR的漏斗图
“forestplot()”函数
用户可以根据需要和兴趣来调整功能相关参数,以绘制更生动的图形。 现在该函数更适合用于固定效果模型的图形操作,通过前面的分析使用随机效应模型示例,因此需要使用固定效应模型进行分析,然后定义labeltext参数,然后再使用函数绘制。
例子2
研究美国2000-2006年7年关于 Aspirin如何预防心肌梗塞后死亡率的试验
Rrr=data.frame(study=c("MRC-1","CDP","MRC-2","GASP","PARIS","AMIS","ISIS"),year=c(2000,2001,2002,2003,2004,2005,2006),event.e=c(56,54,103,35,69,298,1600),n.e=c(520,760,980,360,750,2000,9000),event.c=c(52,56,165,26,65,321,1690),n.c=c(624,776,650,230,695,2560,9325))
Rrr
study year event.e n.e event.c n.c
1 MRC-1 2000 56 520 52 624
2 CDP 2001 54 760 56 776
3 MRC-2 2002 103 980 165 650
4 GASP 2003 35 360 26 230
5 PARIS 2004 69 750 65 695
6 AMIS 2005 298 2000 321 2560
7 ISIS 2006 1600 9000 1690 9325
library("metafor")
metaRrr=rma.mh(event.e,n.e,event.c,n.c,data=Rrr,measure="RR",slab=study)
metaRrr
library("metafor")
Loading required package: Matrix
Loading 'metafor' package (version 1.9-9). For an overview
and introduction to the package please type: help(metafor).
> metaRrr=rma.mh(event.e,n.e,event.c,n.c,data=Rrr,measure="RR",slab=study)
> metaRrr
Fixed-Effects Model (k = 7)
Test for Heterogeneity:
Q(df = 6) = 46.9022, p-val < .0001
Model Results (log scale):
estimate se zval pval ci.lb ci.ub
-0.0319 0.0273 -1.1678 0.2429 -0.0854 0.0216
Model Results (RR scale):
estimate ci.lb ci.ub
0.9686 0.9182 1.0219
R软件中metafor 包RR的合并效应量
Forest(metaRrr,trasf=exp)
R软件中metafor 包RR的森林图
funnel(metaRrr)

R软件中metafor 包RR的漏斗图
从这个结果可以看出:在R软件中metafor和meta包中合并效应量RR值为—0.3,RR值95%可信区间是-0.09~0.02。这个区间不包括1,可以认为合并的效应量RR值不等于1,也即:心肌梗塞与病人的死亡率结果是不一样,存在统计学差异。
若漏斗图呈现不对称,而且不对称的程度越大,表示偏倚程度也就越大,治疗效果极可能会被放大。
5.结束语
本文介绍了R语言的一些应用,其中包括R的安装以及包的安装,通过对R软件的应用可以得到对一些数据的统计和绘图来分析,更加容易的得出结论。而且,文中还介绍了几种R软件的数据的输入方法,包括直接输入、文本输入以及从Excel导入。接下来,又介绍了一些meta分析常用的类型,可以从不同的分析得出结论,具有更加有用的比较彼此的差别。R 的基础包中只包含了一些很基本的功能,Meta分析的合并效应量可以汇总好几个研究结果,其中要对研究问题的明确、了解相关的信息并验证关联的研究和标准,从而得出想要结果再汇总基本信息、分析结果得出结论。最后,应用例子通过metafor包、 meta包和rmeta包来得出OR的合并效应量、OR的森林图和OR漏斗图来分析。
